前言
Headless chrome是Google新推出的无界面浏览器。 相比于之前的无界面浏览器,如PhantomJS,headless chrome有着Google大厂维护的先天优势和chrome强大调试工具的后天加成。 随着发展,很可能演化为如Burpsuite一样的web神器。 趁着这次实习,我对headless chrome以及puppeteer,一套专门控制chrome和DevTools的高等级API有了初步的认识,在此将踩过的坑和一些解决问题的思路记录在此。
相关概念简介
headless chrome
也称为无头浏览器,即chrome的无界面版本。 当我们要在没有桌面环境的服务器上运行浏览器或是进行一些自动化测试的时候,我们希望能够操纵一个浏览器来完成工作。 相比起urllib、 requests这些http请求模块,无头浏览器的特点在于其能够渲染DOM树。 因此,无头浏览器被广泛应用在爬虫、 XSS自动化检测等 需求当中。 当headless chrome启动之后,它会默认监听9222端口,接受指令并执行。 headless chrome控制指令遵循Chrome DevTools Protocol协议。 使用这个协议,我们不仅能控制用户鼠标、 键盘事件,得到页面的内容,还可以使用chrome调试工具。 总之,chrome本身能做到的,我们都可以通过DevTools做到。
DevTools Protocol
与无头浏览器交互的协议,可以直接使用websocket与开启的chrome进行通信。 所有的控制指令都以json通信,格式大约是下面的样子:1
2
3
4
5{
"id": id,
"method": command,
"params": params
}
例如,我要要浏览器打开访问一个页面,控制数据如下:1
2
3
4
5{
"id": 2,
"method": "Page.navigate",
"params": {"url": "https://www.github.com"}
}
浏览器便会访问https://www.github.com。 返回的数据也都以json格式传输。 当然,要直接以websocket与chrome交互是非常不方便且不直观的。 为了让控制浏览器跟接近于真实用户,便有了puppeteer和pyppeteer这样的框架。
puppeteer和pyppeteer
鉴于使用Chrome DevTools Protocol非常违反用户操作浏览器的习惯,便有了各种封装好的API。 puppeteer便是Google团队官方提供的API工具,它的特点是:像用户一样操作浏览器。 例如,我们想进行一次搜索功能,习惯是打开一个浏览器,选择一个页面,输入网址并回车,点击其中一个搜索结果,截图并保存,最后关闭浏览器。 这在puppeteer中,可以用如下代码做到:1
2
3
4
5
6
7
8
9
10const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
await page.click("button");
await page.screenshot({path: 'example.png'});
await browser.close();
})();
以上代码无需任何解释,一看便懂,非常符合用户的使用习惯。 因此,pptr上手非常简单。
官方提供的puppeteer是nodejs模块,如果要在python中使用,可以使用pyppeteer。 pyppeteer是puppeteer的python移植版,其作者力求更上puppeteer的所有更新,但是自己不会增加新的特性。 要使用pyppeteer也可以直接翻阅puppeteer的api文档,几乎所有的方法和参数都完全一致。 上面的样例代码在python中的实现如下:1
2
3
4
5
6
7
8
9
10
11
12import asyncio
from pyppeteer import launch
async def main():
browser = await launch()
page = await browser.newPage()
await page.goto('http://example.com')
await page.click("button");
await page.screenshot({'path': 'example.png'})
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
常用技巧
下面介绍一些使用pptr开发过程中常用的一些技巧,这些技巧在XSS扫描和爬虫等应用中相当实用。
拦截请求
在爬虫和XSS扫描中,我们需要更多的与页面交互以触发更多的DOM事件,这其中可能会涉及一些url请求。 如果我们需要对请求进行读取和修改,可以为页面设置拦截器,拦截request和response。 要启用拦截器先必须使用page.setRequestInterception()方法。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19await page.setRequestInterception(True)
async def request_handler(request):
if meta['method'] == 'POST':
overrides = {
'method': 'POST',
'postData': meta['data'],
}
await request.continue_(overrides=overrides)
else:
await request.continue_()
page.on("request", request_handler)
async def response_handler(response):
if response.status == 404 and response.url == meta['url']:
print("GOT NEW RESPONSE 404")
self.is_404 = True
page.on('response', response_handler)
在上面的例子中,我使用拦截器来讲get请求修改为post请求。 原因是pptr中的goto方法只能够发起get请求,要修改headers和cookies,或者将请求方法改为post,可以用request.continue_(overrides=overrides)修改。
植入js代码
有时我们需要在页面中执行一些js代码进行查询或运算,然后获得返回结果。 可以用page.evaluate()方法植入js代码执行。 例如,我用如下代码检测web应用前端框架:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18framework = await page.evaluate('''() =>{
let framework = {}
try{
$("head");
framework['jquery'] = true;
}
catch(err){
framework['jquery'] = false;
}
try{
angular.module;
framework['angular'] = true;
}
catch(err){
framework['angular'] = false;
}
return framework;
}''')
上述evaluate方法与前面使用同一个上下文。 如果要在新的上下文运行,可以使用page.evaluateOnNewDocument()方法。
注册函数
进行XSS测试的时候,我们通常会注入类似<script>alert(1);</script>这样的代码,但alert函数被各种waf过滤,所以我推荐注册一个新的函数以防被waf过滤。 代码如下:1
2
3
4
5
6
7def report(message):
if message == 1:
print("[+++++++++++] FOUND XSS!!!")
self.found_xss = True
report_bug(method, url, data)
await page.exposeFunction('holive', lambda message: report(message))
注册完毕之后,我们可以以<script>holive(1);</script>作为payload。 若代码被执行,我们注册的函数便会回调并且上报漏洞。
使用开发者工具
我在开发过程中遇到这样一个需求:给定一个DOM节点,返回该节点注册的所有事件。 这在chrome的开发者工具中,可以直接用getEventListener()方法访问: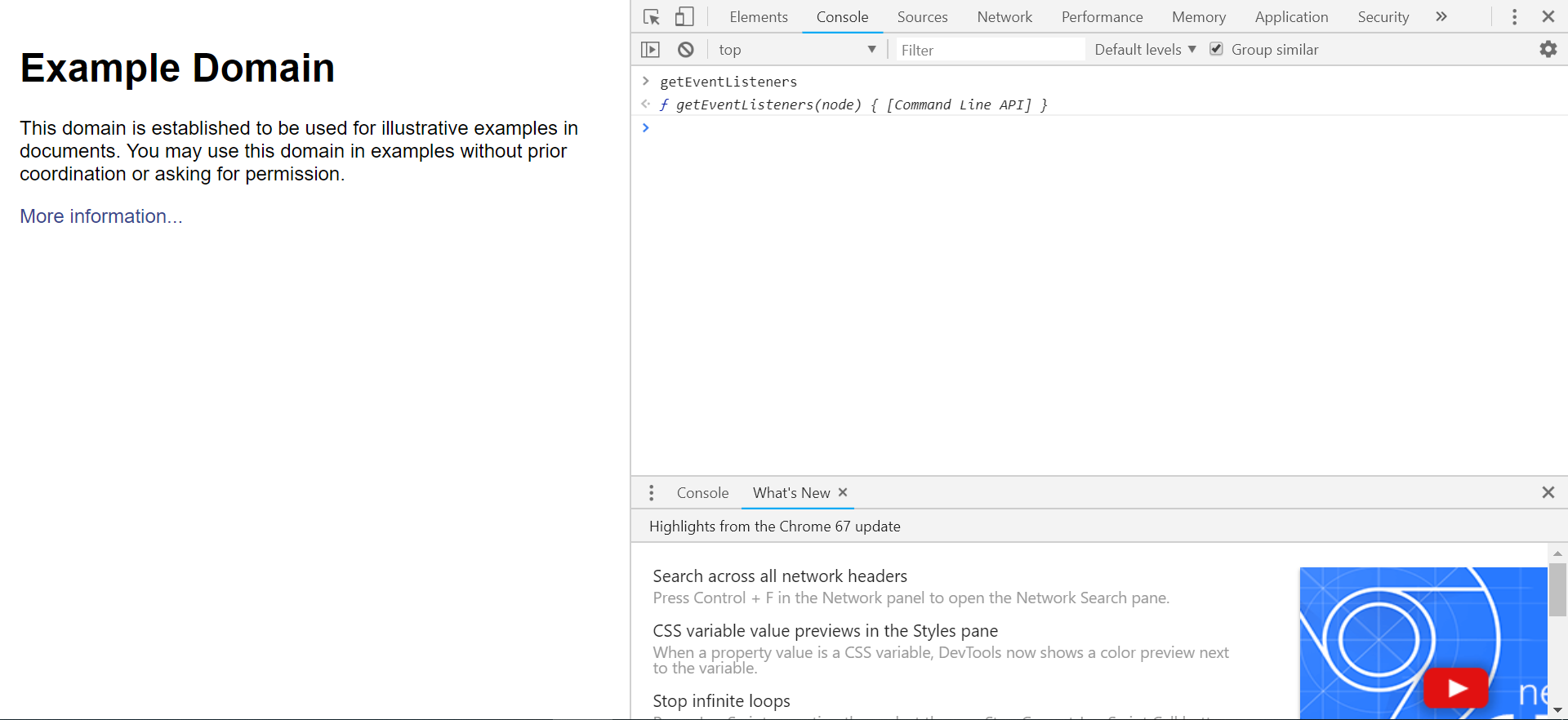
然而,在js中我们并不能调用这个方法。 那么要怎么访问这个方法呢?查询Chrome DevTools Protocol,我们发现了这个方法: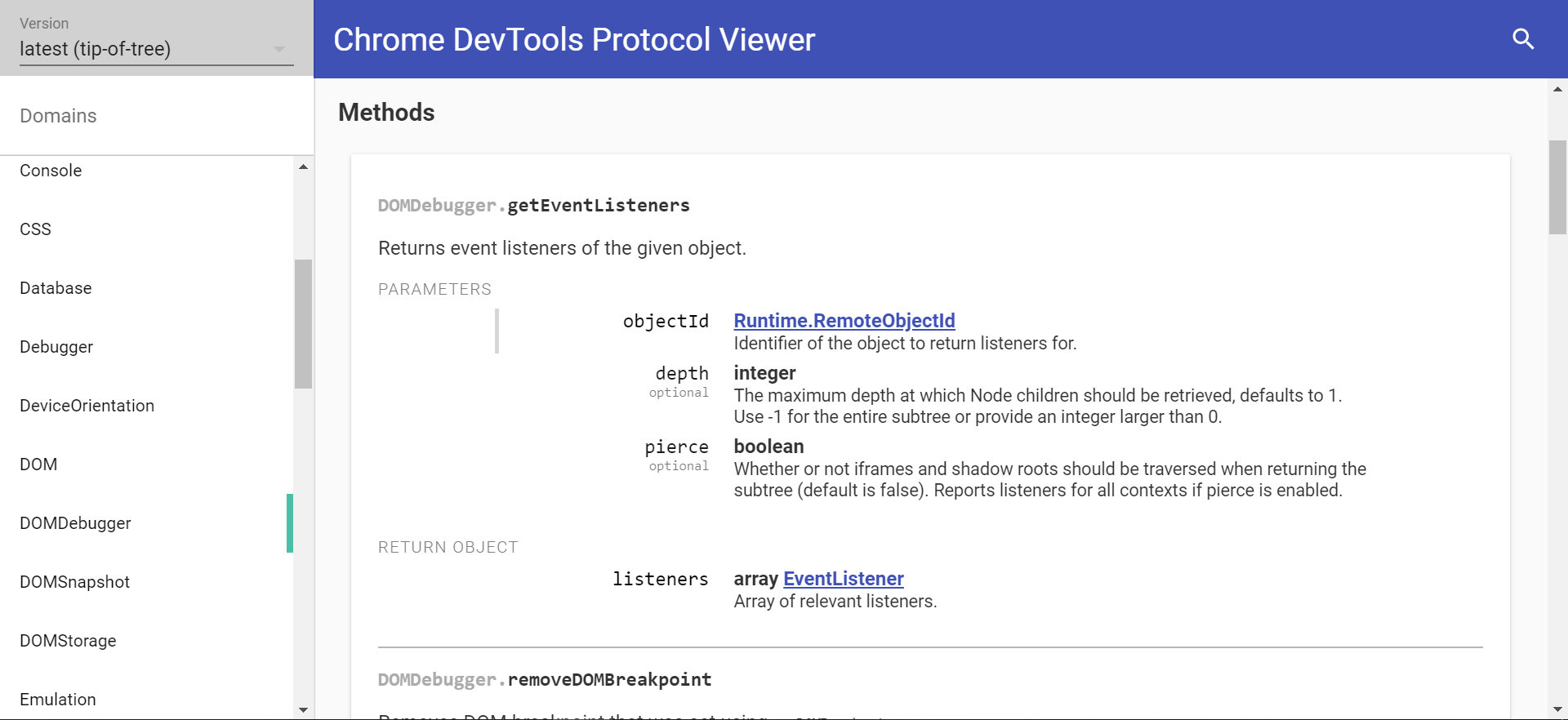
遗憾的是,pptr也没有封装这个函数。 但pptr给我们提供了一个创建Chrome DevTools Protocol session的接口, 通过这个session,我们可以直接使用DevTools Protocol下发控制指令。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({headless: false,args: ['--ignore-certificate-errors', '--disable-web-security', '--allow-running-insecure-content', '--disable-xss-auditor', '--no-sandbox', '--disable-setuid-sandbox']});
const page = await browser.newPage();
await page.goto(url);
const client = await page.target().createCDPSession();
await page.focus('input');
let DOM = await client.send('DOM.getDocument');
let nodes = await client.send('DOM.querySelectorAll',{nodeId: DOM.root.nodeId,selector: "#ww"});
let obj = await client.send('DOM.resolveNode',{nodeId:nodes.nodeIds[0]});
await page.keyboard.type("payload");
let listener = await client.send('DOMDebugger.getEventListeners', {objectId: obj.object.objectId}).catch(e=>{console.log(e)});
console.log(listener);
})()
使用插件
有时候,我们可能会遇到一些chrome本身也没有提供的功能。 例如,我们希望爬虫能够和页面进行交互,但是不希望页面进行url跳转。 这在chrome中也没有很好的解决方案。 这时候我们就需要用到chrome的插件功能。 启用chrome插件非常简单,在启动浏览器时添加两个参数即可:1
2
3
4browser = await launch({"headless": False,
"executablePath": "./chrome-win32/chrome.exe",
"args": ['--load-extension=../chrome_extension/',
'--disable-extensions-except=../chrome_extension/',]})
注意这里插件的位置必须是对于chrome.exe文件的相对路径。 我们使用Chrome navigation lock extension中一位大牛介绍的浏览器锁插件来限制浏览器跳转,插件的下载地址如下:https://gist.github.com/GuilloOme/2bd651e5154407d2d2165278d5cd7cdb。 按照说明配置好插件后,运行其中的index.js进行测试,点击其中的链接,发现页面并不会跳转,而跳转的目标会在console中打印。 效果如下: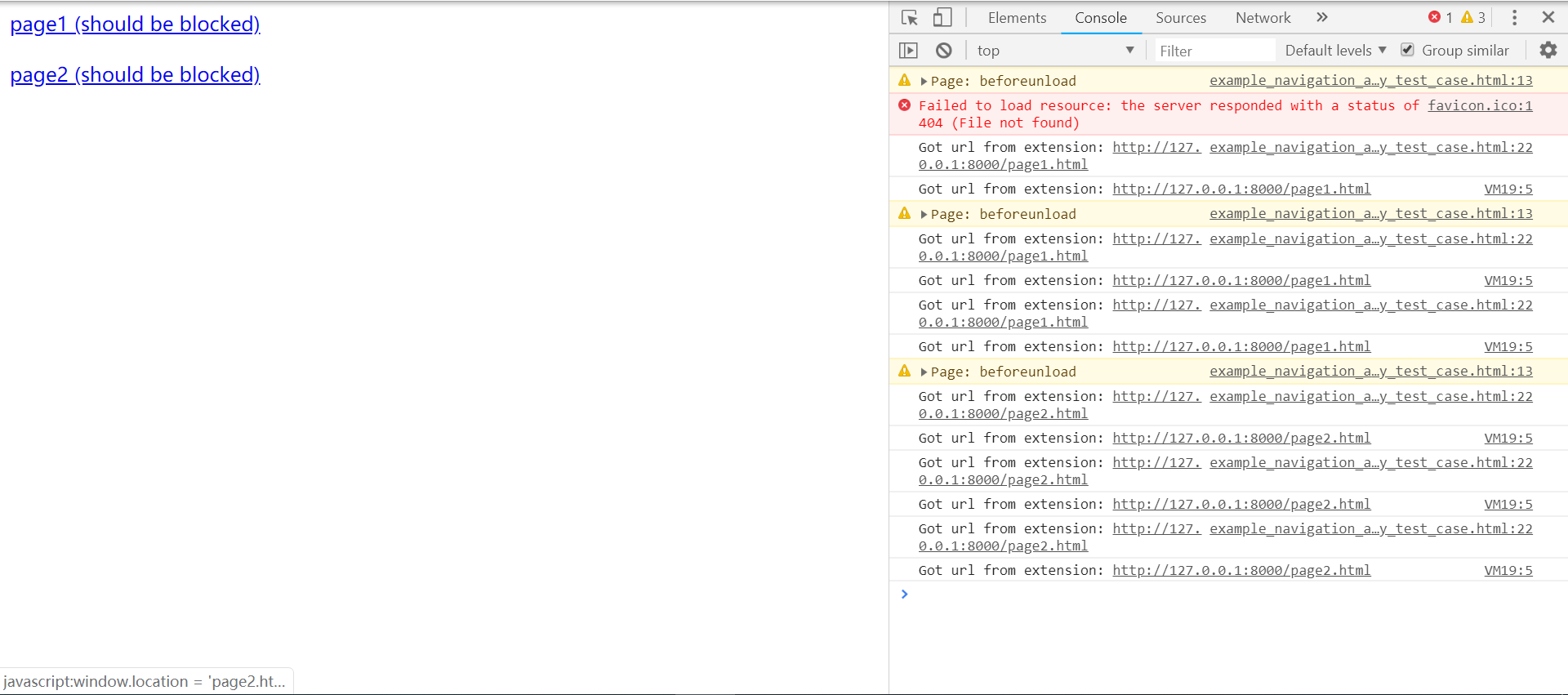
踩过的坑
Linux主机上chrome无法下载
使用pptr时,如果没有指定executablePath,pptr会自动下载chrome。 然而这个源是国外的源,很有可能无法下载。 遇到这种情况,可以去pptr的downloader里面找一下下载地址和存放路径:https://storage.googleapis.com/chromium-browser-snapshots/Linux_x64/571375/chrome-linux.zip
,手动下载好之后放到指定目录上去便可。 例如我的机器上存放路径为:/root/.pyppeteer/local-chromium/571375/chrome-linux/
浏览器error:failed to connect to browser port
手动安装好chrome之后,发现无法运行官网的demo文件,并显示failed to connect to browser port。 这是chrome没有正常启动所致,要在启动chrome的参数中加上--no-sandbox方可正常运行。
pyppeteer与puppeteer执行evaluate的不一致
按照github上pyppeteer的项目介绍,pyppeteer应该是与puppeteer的所有api保持一致。 但我在开发过程中遇到这样一个奇怪的问题,两段等效的代码在pyppeteer中和puppeteer中运行得到的结果不同。 有兴趣可以跟进我在github上给pyppeteer作者的留言,地址:https://github.com/miyakogi/pyppeteer/issues/120
后话
在headless chrome和pptr的使用过程中,我确实感受到了操控一个浏览器为各种测试带来的便利。 我相信不久的将来,headless chrome将成为web安全中必不可少的工具。 然而,在目前的使用中,我认为有两点是pptr和headless chrome还不够好的。 第一是对请求和响应的控制还不够方便。 现在要修改http请求头或者使用post方式全球,只能通过拦截request来做修改。 但对于response,我们是没有办法进行修改的。 也就是说,如果我们想对于返回的response中注入一段js代码,pptr无法实现,必须通过插件才能做到。 第二则是对于鼠标的控制非常不友好。 在DevTools Protocol中鼠标相关的方法我们都要输入x、y坐标作为参数,非常不方便。 但DOM树中鼠标事件有很多,使得现在要像用户一样移动鼠标比较困难。 这两点还值得改进。